
Our Approach to AI Safety and Security
By Alexander Berger and Emily Oehlsen
Editor’s note: This article was published under our former name, Open Philanthropy.
Introduction
In Part 1 of this essay series, we discussed our approach to accelerating science and technology while mitigating potential risks, covering the following topics:
- Why and how we invest in accelerating scientific and technological progress. Science and technology have been essential to improving human well-being, and philanthropy can play an important role in supporting R&D, improving policy, and accelerating technological spillover to populations that lack market power.
- How safety itself represents a form of progress, and how improvements in safety can accelerate progress. Advancements in safety can make new technologies more useful and functional, provide social license for technological adoption, and prevent catastrophes that could halt progress altogether.
- Why we focus on reducing worst-case risks from AI. Well-targeted philanthropy often responds to socially important market failures, and despite its enormous significance there are comparatively weak commercial incentives for firms to invest in AI safety and security.
This post focuses on the specific strategies and grantmaking approaches we use to reduce worst-case potential risks from advanced AI. We cover:
- Our early work on AI safety. Open Philanthropy began supporting AI safety and security work in 2015, when the field was in its early stages. We focused on building institutions and supporting talent pipelines for experts working in relevant fields. (More)
- How things have changed since then. AI capabilities have advanced significantly, expert concern around major risks from upcoming AI systems has become more widespread, and philanthropic opportunities to improve safety and security have grown. (More)
- Our current approach. Our grantmaking strategy focuses on improving societal visibility into AI capabilities and risks, developing technical and policy safeguards to mitigate risks, and investing in the talent and institutional capacity needed to address these challenges. (More)
Early days
Open Philanthropy began working on AI safety in 2015, when few philanthropists were engaged in the field. AI itself was at a relatively early stage compared to today — this was two years before the introduction of the transformer architecture that underpins modern language models, and seven years before the launch of ChatGPT in 2022. Based in part on the rate of progress at the time, we estimated in 2016 that there was at least a 10% chance that transformative AI, by which we meant AI systems capable of driving changes at least as significant as the Industrial Revolution, could arrive within 20 years (i.e. by 2036). We thought then, as we do now, that the most likely outcomes from AI were positive, but we were concerned about the risks posed by rapid AI development.
Because the fields of AI safety and security were nascent when we first got involved, there weren’t many obvious interventions to make to improve outcomes from the development of transformative AI. Luke Muehlhauser, our program director for AI governance and policy, described the profound uncertainty in a 2020 blog post:
Would tighter regulation of AI technologies in the U.S. and Europe meaningfully reduce catastrophic risks, or would it increase them by (e.g.) privileging AI development in states that typically have lower safety standards and a less cooperative approach to technological development? Would broadly accelerating AI development increase the odds of good outcomes from transformative AI, e.g. because faster economic growth leads to more positive-sum political dynamics, or would it increase catastrophic risk, e.g. because it would leave less time to develop, test, and deploy the technical and governance solutions needed to successfully manage transformative AI?
Given this uncertainty, we focused on supporting academic research, setting up institutions to investigate potentially useful policy responses, and building talent pipelines for people working on the issue. We aimed to give grantees substantial flexibility in pursuing approaches that they thought were promising, and as a result, we funded many grantees who disagreed about both the nature of risks posed by AI and the best ways to mitigate those risks. We saw this as a feature of our approach, not a bug.
Updates since then
Since our early involvement in AI safety and security grantmaking, the field has changed in a few key ways.
First, AI has advanced at a rapid pace. Benchmarks to measure AI progress are regularly rendered obsolete (see below), and AI agents can now control a browser or computer to perform some tasks without human supervision. There are multiple companies valued in the hundreds of billions of dollars that directly aim to build artificial general intelligence (AGI). Capital expenditures on AI data centers reached over $200 billion in 2024 (up nearly tenfold from 2015) and are expected to increase significantly.[1]A recent forecast found that AI data center expenditures would reach $1 trillion by 2027. A report from Epoch AI found that the largest AI supercomputer in 2030 alone would likely cost $200b. Another report from McKinsey projected that demand for AI-related data centers will reach between $3.7t and … Continue reading At the time of writing, users of the Metaculus forecasting platform put the median date of reaching AGI at June 2033.[2]Some of our earlier views about AI progress felt radical when we first got started, but now seem accurate or even conservative in retrospect. For example, the 2016 blog post referenced earlier gave a 10% chance of transformative AI by 2036, which felt very bold at the time. While there’s a lot of … Continue reading (The growing economic importance of AI has also led to a new and well-financed opposition to many AI safety efforts.)
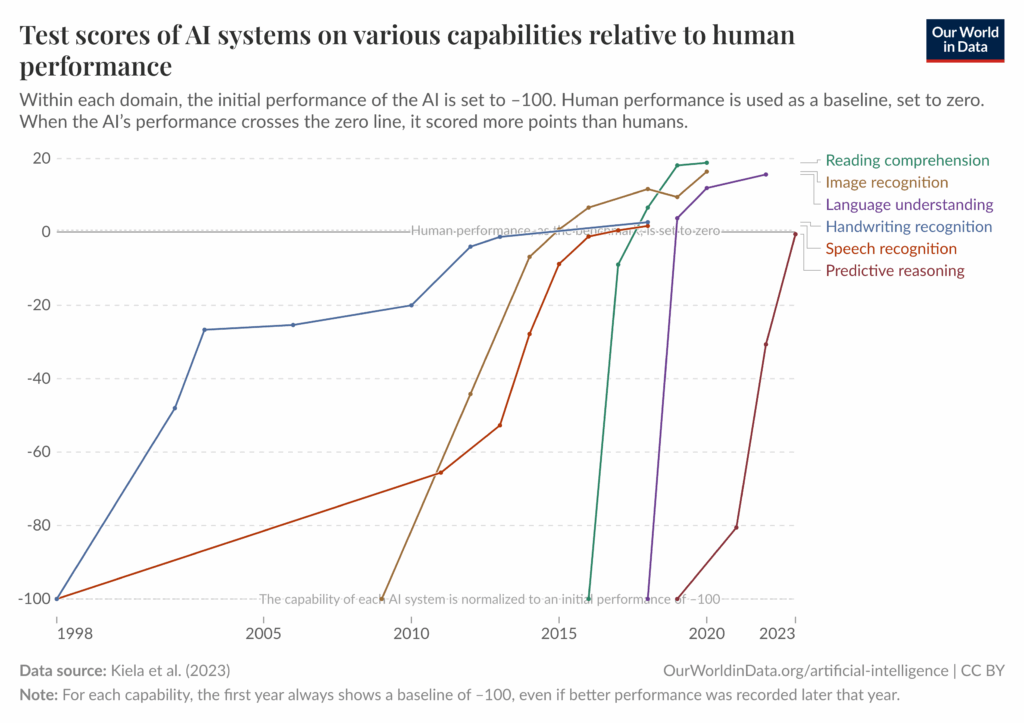
Second, there is greater agreement about some of the worst-case risks posed by transformative AI. Leading AI companies openly acknowledge they don’t understand how their systems work internally or how they can be reliably controlled (see example statements: OpenAI, Google DeepMind, and Anthropic).[3]Some relevant quotes: In 2023, OpenAI stated, “Currently, we don’t have a solution for steering or controlling a potentially superintelligent AI, and preventing it from going rogue,” and in May 2024, after discussing the need for extended pre-deployment safety testing and stronger … Continue reading The leaders of these companies, including Sam Altman of OpenAI, Demis Hassabis of Google DeepMind, and Dario Amodei of Anthropic, have all said that mitigating the risk of catastrophic outcomes from AI should be a global priority on par with other global priorities like avoiding nuclear war. Prominent AI researchers like Geoffrey Hinton, Yoshua Bengio, and Stuart Russell have pivoted their work toward AI safety.
We’re particularly concerned about risk pathways that look like:
- Extreme misuse of AI technology, e.g. in designing bioweapons or enabling authoritarian control. AI could help bad actors engineer far more lethal and transmissible pathogens than those found in nature, or help authoritarian regimes use advanced surveillance and personalized propaganda to entrench political control.
- Scenarios where humanity loses control of advanced AI agents. As AI systems grow more capable, we may hand over critical decisions faster than we can safely manage.
- Rapid changes that strain institutions and lead to global security threats. Military and information systems could change so quickly that the international community wouldn’t have time to react, leading to profound instability and risk of inadvertent escalation during moments of crisis.
Third, new empirical evidence is starting to emerge about these risks. Current AI systems have exhibited misaligned behaviors, including reward hacking and strategic behavior to avoid being retrained, even in relatively simple training environments. AI systems have rapidly improved at virology, which could yield scientific breakthroughs but could also pose future biological risks. There have also been early indications that AI systems could soon automate software engineering; early modeling suggests this could lead to a powerful feedback loop that dramatically accelerates further progress.
Finally, AI has grown significantly in geopolitical importance. We expected that advanced AI would be a source of intense economic and military competition, and since the release of ChatGPT, governments (especially the U.S. and China) have begun to prioritize AI competitiveness and semiconductor access. We think it is very important for democracies to maintain their competitive advantage in AI over authoritarian countries.
Our current approach to AI safety and security
There is still substantial uncertainty and expert disagreement about the future of AI, how quickly it will progress, and how different policy levers might shape risks and benefits. In light of that, we aim to take an iterative approach, testing out different theories of change and adapting our strategy based on what we learn. Our work today is guided by the following principles:
- Focus on the highest-stakes risks. One thing that hasn’t changed since our early days is that we are focused on the highest-stakes risks posed by transformative AI, like catastrophic misuse or loss of control. We believe reducing these risks is the most important way that OP can help ensure society is well placed to harness the benefits and manage the challenges associated with widespread deployment of AI.
- Ensure work in this domain remains bipartisan. We think that attempts to pull “safety” into straightforward partisan frames are a mistake. Everyone benefits from avoiding catastrophic outcomes, and given the structure of U.S. government policymaking, it’s crucial to preserve the prospect of bipartisan support for commonsense safety efforts.
- Support a wide range of experts, including those who disagree with us and each other. While we think it’s important to take clear stances when we have them, we aim to support a wide range of actors in the space so that the best ideas can win out over time. For instance, a 2024 Politico article discussed a paper from researchers who found that AI language models could help people with little or no lab training develop new pathogens, alongside a paper from RAND that found current language models didn’t substantially increase the risk of a biological attack. While the two papers look at somewhat different conditions, they point in opposite directions regarding AI’s impact on biorisk. Both papers were produced by groups we’ve funded. Additionally, we held a contest for essays that would influence our views on AI risk and awarded the top prize to the Forecasting Research Institute for a paper that strongly challenged our thinking at the time.
There are some nuances to our approach that we want to emphasize:
- We support work to realize the benefits of AI, even as we also focus on mitigating risks. Just as there are market failures around mitigating risks from AI, there are sometimes market failures around the upsides — particularly around accelerating global public goods that lack large markets, like scientific research and products that address neglected diseases. For instance, we’ve supported David Baker’s work on using AI to develop vaccines for diseases like hepatitis C and syphilis. We expect the number of promising opportunities in this space to grow over time.
- We want regulation to be proportionate to the risks posed and often feel that proposed regulation targeting smaller-scale harms is overly restrictive. Given AI’s national security implications and the catastrophic risks it poses, we think governments have a crucial role to play; there are many policy levers they can and should use right now to reduce those risks. At the same time, we are not uncritically supportive of all AI regulation, and in practice we are typically skeptical of regulation that we don’t think will move the needle on reducing the worst-case risks.
Guided by these considerations, our grantmaking approach is focused on laying the groundwork for society to manage extreme risks from AI. We categorize this work into three pillars: increasing visibility into emerging capabilities, designing safeguards to prevent worst-case scenarios, and strengthening the field’s capacity to respond.
Visibility
Visibility into cutting-edge AI R&D is essential for understanding the trajectory of AI capabilities and their risks and benefits, ultimately allowing for more informed decision-making by companies, civil society, and governments.
Unlike most companies, frontier AI companies can’t fully predict what their products will be capable of until after they’ve been developed. Without visibility into frontier AI capabilities, we risk being blindsided by rapid capability advances that outpace safety measures. For example, OpenAI and Anthropic said in February 2025 that their models are approaching risk thresholds for aiding in the design of biological weapons. It may soon be possible for a company to create a model that can conduct sophisticated biological research, like discovering novel pathogens. Without adequate monitoring, evaluation frameworks, or reporting mechanisms, these capabilities might only be discovered when the model is already being used by thousands or even millions of people. At that point, malicious actors may already be able to use these systems to design biological threats or compromise critical infrastructure.
One key example of work in this area is frontier AI model evaluations, which involve systematic assessments of their capabilities and risks. Specific efforts we find valuable, some of which we’ve funded, include:
- Evaluations for scheming, sabotage, and alignment faking, where a model selectively complies with its objective during training to prevent modification of its behavior out of training.
- Evaluations for potentially dangerous capabilities such as cyberoffense and biological research.
- Research on the predictability of large language model (LLM) benchmark performance and on scaling laws for LLM performance.
- Analysis of the benefits of different levels of model access for AI audits.
In addition to evaluations, other work we find valuable for increasing visibility into AI systems and awareness about AI progress includes:
- Strategic analysis and threat modeling related to catastrophic risks.
- Frameworks for forecasting transformative AI timelines and takeoff speeds.
- Building broad public awareness and understanding of the trajectory of AI development and the risks that AI could pose.
- High-quality journalism about the trajectory of AI development.
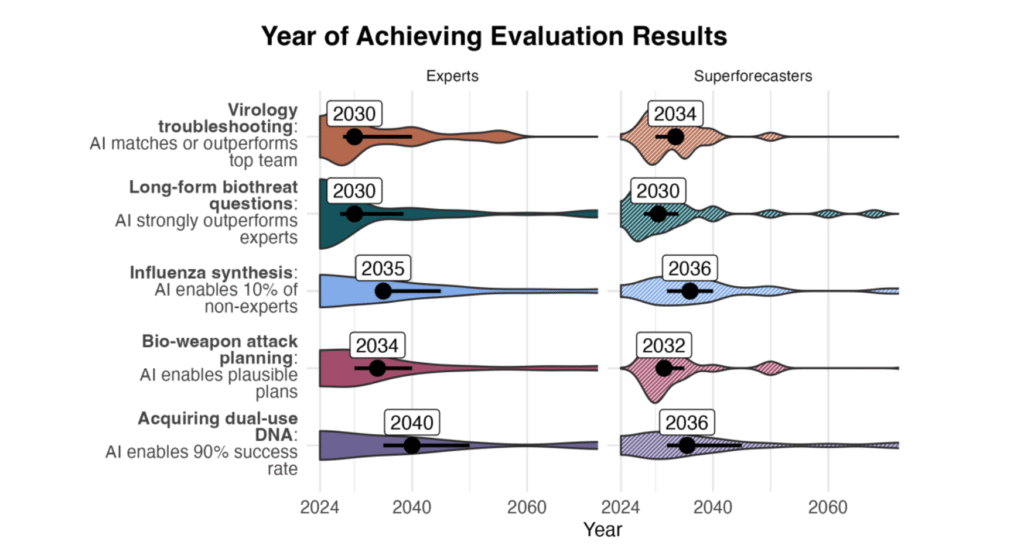
Safeguards
To make worst-case scenarios less likely, it’s important to design and implement technological and policy safeguards that protect against worst-case risks.
While evaluations can help identify the risks of new AI systems, we need safeguards to actually mitigate those risks. As companies race to develop more powerful models, safety measures often receive far less investment and attention despite their importance to society. The consequences of safety failures will likely grow more severe as systems become more capable of autonomous action and strategic planning. Some of these issues exist in today’s relatively limited systems, and the challenge will intensify as models become more powerful and autonomous.
Supporting technical safety and security methods is one key example of work in this area. Recent advancements in AI capabilities have allowed researchers to actually study concrete examples of long-predicted risks from AI systems like alignment faking or exploiting limitations of human oversight. Research that we find valuable, some of which we have funded, includes:
- Training AI systems to act in helpful, honest, and harmless ways through scalable oversight techniques, constitutional AI, and other frameworks.
- Detecting or mitigating undesirable AI behaviors using techniques such as classifiers for harmful outputs or actions, control protocols, and various forms of interpretability.
- Preventing users from accessing dangerous capabilities through adversarial robustness research, security mitigations for jailbreaks, and tamper-resistance methods.
- Information security measures for preventing unintended proliferation of dangerous AI systems.
You can see our recent $40 million technical AI safety RFP for more on areas we think are promising.
We also work to promote safeguards in policy and governance. Examples of work we find valuable here, some but not all of which we have funded, include:
- Private governance initiatives
- The development of the if-then structure for frontier AI safety policies, by e.g. Anthropic, Model Evaluation & Threat Research (METR), the UK’s Department for Science, Innovation, and Technology (DSIT), OpenAI, Google DeepMind, and the Carnegie Endowment for International Peace (CEIP)
- Safety standards development by the Frontier Model Forum
- National policy work
- Supporting academic centers and think tanks that serve as institutional homes for AI safety and security researchers
- Research and policy frameworks that identify key challenges governments face when regulating the riskiest AI models and/or propose solutions to those problems
- Proposals to require large AI developers to adopt certain safety and security practices, like the bipartisan Preserving American Dominance in AI Act and California’s SB 53
- Multilateral work, like research into potential international institutions and potential mechanisms for facilitating international coordination
Capacity
We believe governments, companies, and civil society need additional capacity to successfully respond to major AI developments.
Meaningful progress on visibility and safeguards requires work by talented individuals and effective organizations across government, frontier AI companies, academia, and civil society. It also requires rapidly building the new fields of science and practice in AI safety and security, as society needs to meet novel technical and social challenges “on a deadline.” However, the field of AI safety and security faces a severe talent and infrastructure bottleneck. Unlike established fields such as climate science with tens of thousands of researchers, or nuclear safety with decades of institutional knowledge, AI safety lacks both the numbers and institutional infrastructure needed to match the underlying pace of technological development.
One key example of our work in this area is supporting development programs to grow the talent pipeline for AI safety and security, including:
- Fellowship programs that help early-career individuals develop skills and pursue useful career paths in nonprofits, government offices, and AI companies.
- Programs that help individuals build careers in AI safety and governance through activities such as graduate study, self-study, and focused periods of career exploration.
- Career advice for people looking to quickly get into high-impact work in AI safety and security.
Other work in this vein includes:
- Events, conferences, and workshops for burgeoning research fields in AI safety.
- Educational initiatives that provide opportunities to learn about AI safety and governance in depth, creating pathways for individuals interested in entering the field.
Next time
While the field of AI safety and security has made significant progress in recent years, many promising efforts to reduce worst-case risks from AI remain underfunded. In Part 3, we explain why the field urgently needs more philanthropic support — and how new funders can play a critical role in shaping the future.
Footnotes